
Spring AI is a Spring Boot library that allows you to easily integrate artificial intelligence models into your applications, facilitating the connection with different artificial intelligence models, whether in the cloud or locally.
What is it?
The purpose of Spring AI is to make it easier for Java developers to use generative AI without having to directly manage the APIs for each vendor's different models, as each one can have different uses and configurations. This saves time and allows for code reuse, allowing developers to switch AI engines without having to rewrite the entire code.
Spring AI is not an AI model in itself; it does not run models or store data, but rather is responsible for sending requests to AI providers and receiving responses ready in the form of objects for use in our application.
How does it work?
For this explanation, we will use a local server with Olma and the Llama3.1 model. However, the framework's operation is practically the same regardless of our chosen provider and model.
1. Project dependency:
The appropriate dependencies must be used depending on the specific provider you want to use, as well as the configuration so that the application can start or the clients can be used.
Dependency to use Ollama as a server: on ChatModel and ToolCallbacks

2. Configuration:
Configuration is done through properties files such as application.yml or application.properties.
It is done under the base property of spring.ai. …
Just inside that you put the provider and the model you want to use and also the credentials or keys necessary to be able to use it (tokens, api keys, ...)
Providers include OpenAI, Anthropic, Google/Vertex AI, Azure OpenAI, and Ollama/LocalAI.
An example of a basic configuration would be:
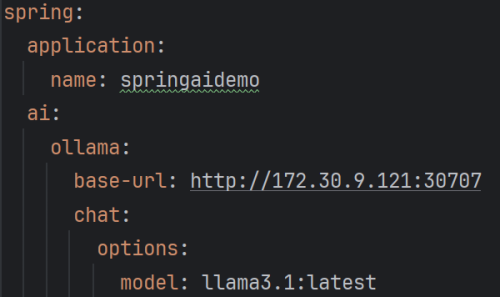
More options can be added within that configuration, parameters such as max-tokens, stop-sequences, temperature, etc.
And you can also add multiple providers in parallel.
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
chat:
options:
model: gpt-4o-mini
ollama:
host: http://localhost:11434
models:
llama2:
model: llama-2-7b
Later we will see other types of configurations, RAG, databases, and other advanced configurations.
Once the provider, model, credentials, etc. have been configured, you can begin with the basic operating example.
3. Basic elements:
At this point, we will cover the basic functionality of the library, always using the chat format as the main one, although other generation possibilities will also be explained.
- ChatModel is the main interface that will be used in this example. All basic chat implementations are based on it, for example OllamaChatModel, OpenAiChatModel, BedrockChatModel, etc.
ChatModel is the way to interact with different LLMs in the form of a chat. It is independent of the AI model used, as it uses the same methods: call, prompt, response, options, etc. Depending on the chosen implementation, the framework will act differently. The main method of the ChatModel interface is the call() method, which receives a Prompt object and returns a ChatResponse object.
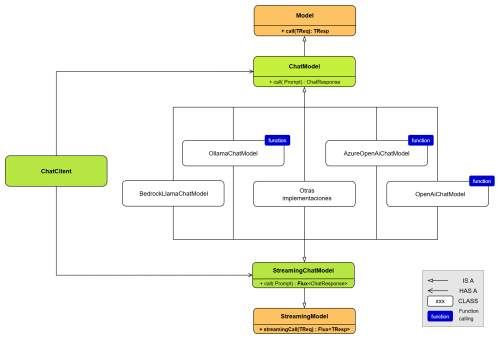
As you can see, this interface extends the Model class, which is the base class from which all models are derived, such as the ImageModel interface (for generating images), DocumentEmbeddingModel (for generating vector embeddings from documents), or AudioTranscriptionModel (for converting audio to text). These interfaces can only be used if the model supports this type of generation; that is, if a model is designed to generate text, it cannot be required to generate images, for example.
The ChatModel implementation used in this example is OllamaChatModel, since Ollama is used in this example. Using the 'spring-ai-ollama-spring-boot-starter' dependency from section 1 automatically creates a bean that creates an object of the OllamaChatModel class, so it doesn't need to be instantiated manually. (The class that creates the initial bean is OllamaAutoConfiguration.)
The main use of OllamaChatModel is its call() method as mentioned above, it is the method used to call the API and it also has other important methods such as getDefaultOptions() or withDefaultOptions() in case you want to have your own instance of OllamaChatModel.
It's also important to explain the ChatClient interface. It's a higher-level interface designed to facilitate interaction with ChatModel. It can be built using builders or another ChatModel, and it facilitates interaction with the model. ChatClient doesn't replace ChatModel; rather, it uses it underneath to offer simpler interaction, ultimately delegating to the same call method as ChatModel. Although it may seem simpler to use, this example explains and uses ChatModel because it allows for greater control, as it works at a more detailed level: prompts, user roles (user, assistant, system), conversation history, model options, etc.
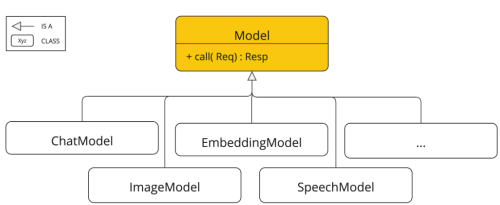
As mentioned before, another important class is the Prompt class, which is the type that receives the ChatModel's call method as a parameter. The Prompt type represents the input given to a language model. It is the container that defines what the model wants to do and how it should interpret it. Its parts are:
- Main content: Text you want the model to process.
- Messages: List of Message objects, each with a role (user, assistant, system) and content, allowing you to build complete conversations.
- Additional options: Parameters such as temperature, maximum tokens, top-k, etc. (depending on the specific implementation of the model).
This class is an implementation of ModelRequest, which, similar to Model, is the base interface from which the rest of the prompt implementations are based, such as ImagePrompt or AudioTranscriptionPrompt.
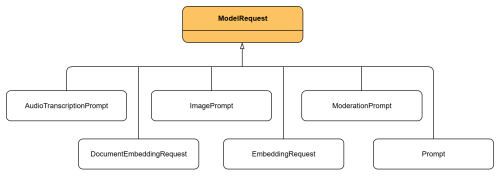
ChatResponse is the class that represents the response returned by a chat model after processing a prompt. It is the type returned by the ChatModel call function; in addition to the generated text, it contains additional information about the response. It is useful because it standardizes the output of a ChatModel regardless of the chosen implementation. Its components are:
- Result: Generation type, this is the main block of the response. It contains the generated content and metadata.
- Output: of type AssistantMessage, the Output stores the actual text generated by the model.
Messages: List of Message objects that contain the conversation history. Each Message has a role and content.
Image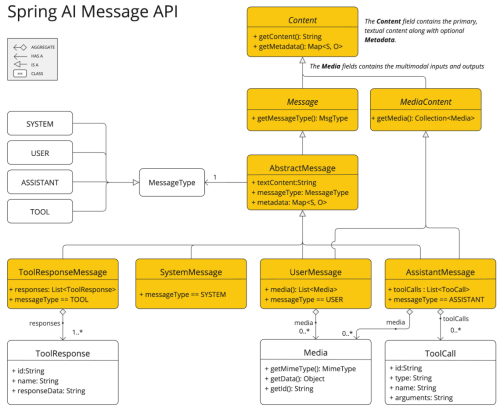
Finally, it's important to explain the Generation class, which represents the specific result of a chat within a ChatResponse and implements the ModelResult interface. Like Model or ModelRequest, ModelResult defines a generic contract for the results of any model. In addition to Generation, there are other ModelResult implementations tailored to different types of models, such as ImageGeneration for image generation or AudioTranscription for audio transcriptions.
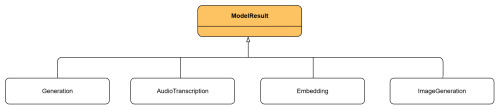
On the other hand, ModelResponse is the interface that represents the generic response of any model in Spring AI. It wraps one or more ModelResults along with any metadata, ensuring a uniform structure. Thanks to it, responses from different models (text, images, embeddings, audio) can be handled consistently under a single contract.

4. Basic workflow:
Now that the main components have been explained, the framework's various functionalities will now be explained. To simplify the code and make it easier to understand, all text has been written in code. However, in a real application, this could be user input, text coming from another function, or any other way of obtaining it; it doesn't always have to be written in code.
- Main use of basic components.
• Simple request and response:
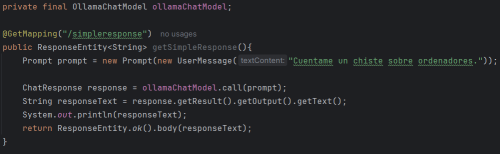
As you can see in the image, the ChatModel of type OllamaChatModel and its main method call are used. This method receives as a parameter a Prompt object created just above, which in turn receives a Message object, in this case a UserMessage. (For simplicity, and since the constructor can receive Strings, it will not be common to see Message objects used in the examples, although it is highly recommended to keep complete control of the conversation). The call function returns a ChatResponse object, and finally, the text of the response is extracted to return it.
• Prompt with parameters:
Arguments can also be passed to the prompt using an object of type PromptTemplate as follows:
A map is created with the variables you want to pass to it and the create function of PromptTemplate is used, which already returns the Prompt type desired by the call function.
• Pass context prior to the prompt:
As explained above, there are several types of Messages, and a list of messages can be passed to the prompt constructor. This is the simplest way to pass context, although other, more efficient ways to enrich a prompt will be explained later.
- Get structured responses.
As explained above, one of the advantages of using this framework is that you can map the response to the desired type, such as List or Map, or a custom type, as shown in the following examples. The response can be converted using Converter objects.
Converter is the main interface from which converters are derived. The following implementations will be used: MapOutputConverter (to convert to a map), ListOutputConverter (to convert to a list), and BeanOutputConverter (to convert to an object of any type).
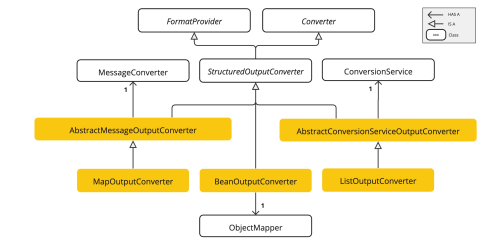
• Using MapOutputConverter:
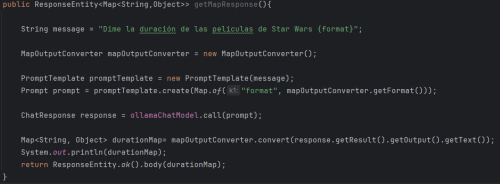
As you can see, the operation is similar to using parameters in the prompt. You use the MapOutputConverter getFormat() function to pass the desired format to the prompt, and finally, you use the convert() method to obtain the desired object type from the response.
• Using ListOutputConverter:
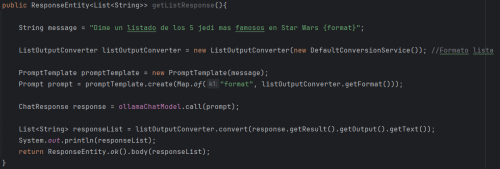
The operation is the same, only the type of Converter has changed, as it is being converted to a list, ListOutputConverter is used.
• Using BeanOutputConverter:
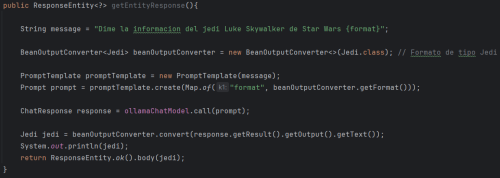
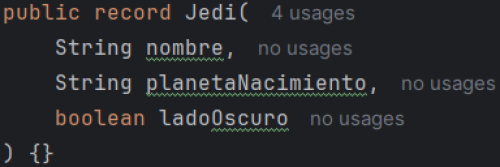
This is the most useful form of conversion since the response can be converted to any type of object needed by the application. In this case, there is a Jedi class to which you want to convert. Simply pass the Jedi type to the BeanOutputConverter and use the methods as in the previous forms of conversion.
- Prompt enrichment
A prompt needs to be enriched when it doesn't have the necessary information to answer the question because the model doesn't have that information. This is usually because the information is very recent or dates later than the last data the model was trained on.
This section will cover three ways to enrich a prompt. The first is when you manually enter data as context into the prompt; the second is when you use a RAG with an external knowledge base; and the third is when you use method calls or tools that provide additional information.
• Provide context to the prompt:
A simple concept, already discussed previously, in this case, it consists of adding a parameter to the prompt with little content. Whether it's handwritten text, a file, etc. The small content is intended to ensure the request doesn't have too many tokens, as this would make requests to models that work with tokens much more expensive. If you have a local model like in this example, adding more content to the question will only slow down the model's response.
• Using a RAG (Retrieval-Augmented Generation)
First you have to understand what this technique consists of.
This is perhaps the most common way to enrich a prompt. It involves searching for relevant information in a collection or database of embeddings and injecting that information into the prompt so that the response is based on this external data and not just on what the model knows.
An embedding is a mathematical representation of a text, image, or audio in the form of a vector of numbers. These vectors are generated in such a way that they express semantic relationships: sentences with similar meanings have nearby vectors in vector space. For example, "car" and "automobile" will be closer than "car" and "giraffe."
When a user asks a question (prompt), that question is also converted into an embedding vector. Once vectorized, the system can compare it with the embeddings stored in the database to find the closest match.
Vector databases are used to save and search for embeddings. In this example, the following types were used:
- In-memory : simple solutions where embeddings are stored in in-memory structures (useful for testing or small volumes).
- Extended databases : some traditional databases such as PostgreSQL offer extensions (e.g. pgvector) that allow you to manage embeddings.
To simplify the whole process, there's the VectorStore interface, which defines functions like add() for storing embeddings, similaritySearch() for searching for similar objects, and delete() for deleting. It allows you to change the database provider (memory, PostgreSQL, etc.) without having to change the code. The implementations used in this example are SimpleVectorStore and PgVectorStore, although there are several others. (An appropriate dependency in the POM is required to use this type of database.)
That said, this is the first way to use SimpleVectorStore. It's important to have the mxbai-embed-large model downloaded.
1. Create the vectorstore.json file that will contain the data:
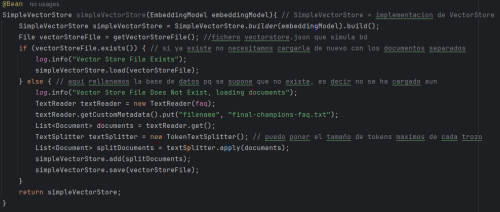
In this case, the bean is created manually in a configuration class. This creates a SimpleVectorStore object with the database. If it doesn't exist, as was the case the first time, this code creates the database, and if it does, it simply returns it. This process may take a few minutes, depending of course on the size of the file you use and the server's performance, since this vector content is generated by the mxbai-embed-large model mentioned above (in this case, and for the example, it's a text file with questions and answers about the Champions League final).
2. Use of this database as RAG:
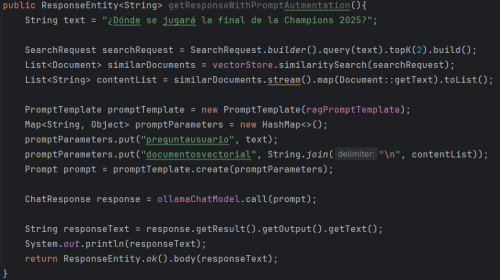
This method applies the RAG pattern: first, the user's question is converted into a query (SearchRequest) that searches the vector database for the most similar documents using vectorStore.similaritySearch. These retrieved documents are transformed into text and integrated into a prompt template (PromptTemplate). Finally, the resulting prompt combines the user's original question with contextual information extracted from the embeddings, so that the model can generate a response based on relevant data and not just its trained knowledge. Finally, the vectorStore variable is of type SimpleVectorStore, even though it does not appear in the image.
The second way to do it with PGVectorStore:
1. Creating the database:
Instructions are provided at the end of the document on how to run the container that holds the database. This container will run a script that creates the basic content, some necessary extensions, the table, and an index.
2. Use of this database as RAG:
The operation of the method is the same, which is why an image of the complete method is not attached. The only difference is that the vectorStore variable is now of type PGVectorStore, since another type of database is being used. However, as can be seen in the previous image, the way to use the methods is exactly the same.
• Method calls
Calling methods is a way to enrich a prompt because it allows you to incorporate additional information into the context the model receives. Instead of limiting itself to just the user's instruction, you can add external data (such as database searches, calculations, queries to third-party services, etc.). This way, the model responds not only with its trained knowledge, but also with more accurate and up-to-date information.
For this technique, known as tool calling, and previously called function calling (deprecated), the framework offers the @Tool annotation, which allows you to mark the specific functions you want the model to use before returning the response. The operation follows the flow shown in the figure.
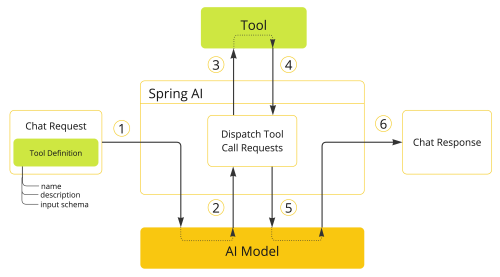
As mentioned above, the main annotation is @Tool, which is used to mark a method as a tool available to the model. It allows you to add a name, description, and metadata within the annotation. This is important because it's what the model will use to decide which function to use, so it must be well-defined and have a clear responsibility. There's also another annotation, @ToolParam, used on method parameters to describe them (name, description, etc.), so the model knows how to invoke the tool correctly.
Examples:
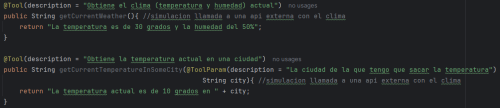
And now the use of these methods, there are two ways to use, the first with ChatClient and tools directly, it is the easiest to use, and the second is with ChatModel and ToolCallbacks.
- First way with ChatClient and tools:
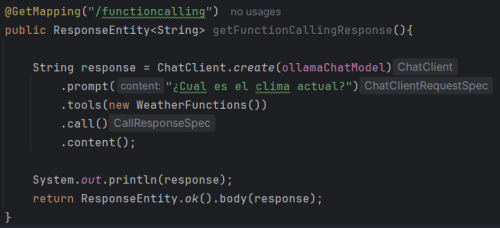
As you can see, the class where the functions are located is passed in the tools function and thanks to the description that has been given to them.
- Second way with ChatModel and ToolCallbacks
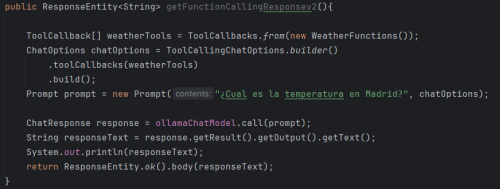
This snippet registers the tools the model can invoke. WeatherFunctions become ToolCallbacks, defining methods available to the model. These callbacks are added to the chat options (ChatOptions), creating a context with the active tools. When constructing the Prompt, the user's question is combined with these options, allowing the model to decide whether to invoke a tool to generate the response.
Conclusion
Spring AI greatly facilitates the development of artificial intelligence applications by providing a layer of unification and consistency that allows you to work with different models without depending on a specific vendor. It offers flexibility and control, allowing applications to generate precise responses tailored to each context. Although the examples primarily work with text, the framework is equally useful for images, audio, and other types of data, greatly expanding the usability possibilities. It also allows you to integrate external actions and combine information from different sources, improving the quality and relevance of responses. Overall, Spring AI provides robustness and ease of maintenance, making it a very powerful tool for building modern, comprehensive AI solutions within the Spring Boot ecosystem.

Francisco Fernández
Software Technician
ALTIA



