
It is designed to work with large volumes of data and process them extremely quickly. Its OLAP architecture allows for complex analyses in real time. It is ideal for cases where large amounts of data are constantly generated and then need to be queried, aggregated, and visualized. Typical examples include counting how many people visit a website, from which locations, and which pages they view most; analyzing how many errors occur in an application; or measuring system performance in real time.
The fact that it's a columnar database gives it a key performance advantage. Instead of storing data by row, as traditional databases do, ClickHouse stores data by columns. This means that when a query is run, only the necessary columns are accessed. This reduces the volume of data read, improves compression, and greatly speeds up operations such as filters, sorts, and aggregations. It also allows you to fully exploit parallelism and CPU and memory usage, making it very efficient even with huge data sets. Some examples of queries it's designed for include:
- Count how many visits there were today: SELECT COUNT(*) FROM visits WHERE date = today()
- Add up the sales of a product: SELECT SUM(sales) FROM sales WHERE product_id = 123
- Count how many errors there were last week: SELECT COUNT(*) FROM errors WHERE date >= today() - 7
- See how many visits there were per country: SELECT country, COUNT(*) FROM visits GROUP BY country
It's a distributed database, meaning it can run on multiple servers simultaneously. This allows it to handle even more data and process it faster, as it divides the workload among multiple machines. Thanks to this architecture, it offers great scalability, allowing the system to grow as needed without losing performance.
Common uses of ClickHouse
- Real-time Dashboards: View updated data instantly, such as the number of connected users or sales of the day. This helps you make quick decisions based on the latest information.
- Real-time analysis: Allows you to analyze events or behaviors as they occur, such as detecting traffic spikes or unusual patterns.
- Business Intelligence: Used to generate reports and summaries that help understand a company's performance, identify trends and plan strategies, facilitating data-driven decision-making.
- Fast data warehouse tier: Functions as a very fast data processing layer within a larger storage system, speeding up queries without impacting the main database.
- Event and Metric Logging : Stores large volumes of system, application, or sensor logs, facilitating monitoring, fault detection, and performance analysis.
- Machine Learning and Data Science: Can be used to prepare and analyze large data sets that are then used in machine learning models or to discover patterns and relationships in the data.
Facility
Getting started with ClickHouse is also simple, considering that ClickHouse works natively on Linux, FreeBSD, and macOS, and on Windows via WSL, you just need to enter the following commands:
- Download it: curl https://clickhouse.com/ | sh
- Start the server: ./clickhouse server
- In another terminal start the client: ./clickhouse client
Additionally, if a graphical environment is desired, we can use clickhouse cloud.
Basic usage example
Basic ClickHouse syntax, you start by creating a database, a table and making some inserts and queries.CREATE DATABASE IF NOT EXISTS prueba_clickhouse;USE prueba_clickhouse;CREATE TABLE IF NOT EXISTS visitas (id UInt64,usuario_id UInt32,pais String,fecha Date,paginas_vistas UInt32) ENGINE = MergeTree()ORDER BY fecha;INSERT INTO visitas VALUES(1, 101, 'España', '2025-06-01', 5),(2, 102, 'México', '2025-06-01', 3),(3, 103, 'Argentina', '2025-06-02', 7),(4, 104, 'España', '2025-06-02', 2),(5, 105, 'Colombia', '2025-06-03', 8);SELECT pais, COUNT(*) AS visitas_totalesFROM visitasGROUP BY paisORDER BY visitas_totales DESC;
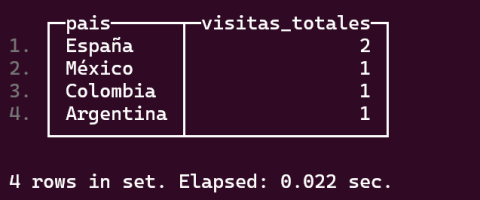
Demonstration
Complete usage example
When working with a ClickHouse database, you have the option of storing that data in our disk-based database or working directly with other data sources. ClickHouse offers integrations with various external sources, such as AWS S3, databases like PostgreSQL, MySQL, or ODBC, and streaming systems like Kafka.
To work with data in S3, there are two options: reading directly from the source, or importing the data into a table in our ClickHouse database and then querying it. Below we show both scenarios:
If you'd like some example datasets, you can consult the official ClickHouse documentation in the Example Datasets section. For this example, we'll query data on New York City taxis in 2015.
1-Data reading
Total number of trips by number of passengers
Now we perform the same queries we performed before but on these local tables:
Total number of trips by number of passengers
Having tables on disk significantly reduces response times because the data is stored directly on the server where the queries are executed, avoiding network latency and potential bottlenecks when accessing external sources. This greatly improves the speed and efficiency of analysis and aggregation.
Storing large volumes of data locally consumes a slight amount of disk space and may require greater hardware capacity, while querying data from external services (such as S3) saves local space but is usually slower and depends on the network connection. Depending on the needs of the project, we can use one way or another of working.
ClickHouse Engines
In ClickHouse, a storage engine defines how data is stored and accessed in a table. Every table needs an engine, and depending on the engine you choose, you'll have different features, performance, and behavior. This is a fundamental concept because the engine
determines whether data is stored on disk, read from an external source, or processed in another way.
MergeTree: This is the most widely used and versatile engine in ClickHouse. It stores data physically on disk and allows for column-based indexing, automatic compression, and good performance in bulk queries and aggregations.
S3: This engine doesn't store data locally; it directly reads files hosted in an S3 (Amazon Simple Storage Service) bucket. This is useful when the data is already stored in the cloud and doesn't need to be imported into a physical table first.
Other engines
Log/TinyLog: Simple engines, storing data in insertion order. Useful for testing or very basic cases.
ExternalTable: Temporary tables for external queries (such as subqueries with IN).
View/MaterializedView: To create normal views or materialized views (with pre-computed data).
Kafka: Allows you to consume data in real time from Kafka topics.
MySQL/PostgreSQL: Engines that allow you to create tables that read data directly from an external database (MySQL or PostgreSQL), useful for integrations without replicating data.
Other interesting facts about how ClickHouse works
Partitions and Segments: MergeTree tables divide data into partitions, typically by date (PARTITION BY), and within these, ordered segments are created (ORDER BY). This makes it easier to delete and read data by time ranges and greatly speeds up searches with filters on key columns.
Primary Key: ClickHouse doesn't have indexes like MySQL, but it uses the primary key to sort data on disk. This key helps skip large blocks of data that don't match the filter and make range queries much more efficient. It doesn't guarantee uniqueness; it's only for sorting and fast searching.
Automatic Compression: ClickHouse compresses data by default (LZ4, ZSTD, etc.). This significantly reduces disk size and allows you to read more data in less time.
Parallel Reading: ClickHouse reads in parallel, using as many CPU cores as possible. It divides the data into chunks and processes them simultaneously, resulting in a significant performance boost.
Examples of ClickHouse connections to PostgreSQL or MySQL
SELECT * FROM postgresql( 'localhost:5432', 'my_database', 'my_table', 'postgresql_user', 'password');
SELECT * FROM mysql( 'localhost:3306', 'my_database', 'my_table', 'postgresql_user', 'password');
Performance comparison
10 million rows:
In the previous example, a table with 3 columns has been created, the same conditions for both databases, and the read query is SELECT count(*) from muchos_datos;
As we can clearly see, the read and write performance in ClickHouse is much higher than in PostgreSQL due to the main characteristics of the database.
The fact that insertion takes less time is because ClickHouse accumulates rows in blocks and inserts them directly, making writing faster instead of writing many rows individually. Furthermore, ClickHouse doesn't write to the WAL for each operation, as other databases do. Finally, one of the things that makes insertion faster is that internal storage is done by columns and compressed.
Possibility of integration in Kubernetes
ClickHouse can be seamlessly integrated with Kubernetes to take advantage of its scalability, automated deployment, and resource management. Some key ideas of what you can do with ClickHouse within a Kubernetes environment are:
- Automated deployment: You can easily deploy ClickHouse as a StatefulSet, using official or custom Helm charts. This allows for nodes with persistent storage and consistent configuration.
- Horizontal scalability: In Kubernetes, you can scale ClickHouse by adding more node replicas, both for reading and writing, and distributing data across them. This is especially useful for heavy analytics workloads.
- High availability: By combining ClickHouse with services like Zookeeper and internal replication, you can have a distributed cluster with fault tolerance and automatic failover within the Kubernetes cluster.
- Microservices Integration: You can have microservices query or insert into ClickHouse directly from other pods.
- Monitoring and Metrics: You can use Prometheus + Grafana to monitor ClickHouse from Kubernetes, as it exposes HTTP metrics. This helps you monitor performance and detect bottlenecks.
- Efficient storage configuration: You can allocate fast, large persistent volumes (PVCs) for your data, and leverage the fine-grained control of Kubernetes to balance performance and cost.
Conclusion
ClickHouse stands out for its excellent performance in processing large volumes of data in record time, making it especially useful in scenarios where query speed is critical. It's a great choice when you need to obtain metrics, aggregations, or complex analyses in near real time, such as in monitoring systems, user analytics, log processing, and more.
Its efficiency makes it a very useful option when other relational databases fall short in response times when dealing with massive datasets. It also fits very well in modern and distributed environments, thanks to its ability to integrate with other sources and operate seamlessly.
scalable in the cloud or on Kubernetes. Therefore, using ClickHouse makes a lot of sense when the focus is on read speed, massive analysis, and scalability.
Want to know more about Hunters?
Being a Hunter means accepting the challenge of testing new solutions that deliver differentiated results. Join the Hunters program and become part of a cross-functional group capable of generating and transferring knowledge.
Get ahead of the digital solutions that will drive our growth. Find more information about Hunters on the website.

Francisco Fernández
Software Technician
Altia



