
¿Qué es Redpanda?
En los últimos años, las arquitecturas modernas han evolucionado hacia sistemas cada vez más distribuidos, donde decenas o incluso cientos de aplicaciones necesitan intercambiar información en tiempo real. En ese contexto surge Redpanda, una plataforma de streaming de mensajes diseñada para transportar datos de forma rápida, escalable y eficiente entre distintos servicios y aplicaciones.
Redpanda puede entenderse como una infraestructura central de comunicación para sistemas modernos. Su función principal es recibir, almacenar y distribuir mensaje en tiempo real. Un mensaje puede ser prácticamente cualquier acción generada dentro de una plataforma digital, por ejemplo: un usuario que inicia sesión, un pago realizado, un pedido creado, un sensor IoT enviando datos o una aplicación generando logs. Todo esto ocurre en cuestión de milisegundos y de forma desacoplada.
Aunque frecuentemente se compara con Apache Kafka, Redpanda no es simplemente “otro Kafka”. Su objetivo es ofrecer las mismas capacidades de streaming de datos y compatibilidad con el ecosistema Kafka, pero eliminando gran parte de la complejidad operativa que tradicionalmente ha acompañado a este tipo de tecnologías.
Una de las principales diferencias es su arquitectura. Mientras Kafka fue construido sobre Java y durante años dependió de componentes adicionales como ZooKeeper, Redpanda fue desarrollado desde cero en C++ con un enfoque mucho más moderno y optimizado para hardware actual y entornos cloud. Esto le permite ofrecer una menor latencia, un uso más eficiente de CPU y memoria, y despliegues considerablemente más simples.
Además, Redpanda mantiene compatibilidad con las APIs y herramientas del ecosistema Kafka. Esto significa que muchas aplicaciones, clientes, conectores y pipelines ya existentes pueden funcionar sobre Redpanda sin necesidad de grandes modificaciones. En la práctica, esto facilita que las empresas puedan adoptar la tecnología sin rehacer toda su infraestructura de datos.
Otro aspecto importante es su enfoque hacia la simplicidad. Redpanda busca reducir la carga operativa asociada a plataformas de streaming tradicionales. Se instala y ejecuta como un único binario, requiere menos configuración y está diseñado para minimizar tareas de mantenimiento, algo especialmente valioso en entornos cloud y arquitecturas de microservicios.
Gracias a estas características, Redpanda ha ganado popularidad en sectores donde el procesamiento en tiempo real es crítico, como plataformas SaaS, fintech, observabilidad, inteligencia artificial, IoT o sistemas de analítica avanzada. Su propuesta de valor combina alto rendimiento, compatibilidad con Kafka y una experiencia operativa mucho más ligera.
En definitiva, Redpanda representa una nueva generación de plataformas de streaming de datos: tecnologías pensadas para mover grandes volúmenes de información en tiempo real, pero adaptadas a las necesidades actuales de simplicidad, escalabilidad y eficiencia.
El problema que intenta resolver
El crecimiento de las arquitecturas distribuidas, los microservicios y las aplicaciones en tiempo real ha provocado que las empresas necesiten mover cantidades masivas de datos de manera constante entre sistemas. Hoy en día, prácticamente cualquier plataforma digital genera mensajes continuamente: usuarios navegando por una aplicación, pagos procesados, sensores enviando información, servicios comunicándose entre sí o sistemas registrando actividad para monitorización y analítica.
Durante años, tecnologías como Apache Kafka se convirtieron en el estándar para resolver este problema. Kafka permitió construir plataformas altamente escalables capaces de procesar millones de mensajes por segundo, convirtiéndose en una pieza fundamental dentro de muchas arquitecturas modernas. Sin embargo, a medida que su adopción crecía, también comenzaron a aparecer ciertas dificultades relacionadas con su operación y mantenimiento.
Uno de los principales problemas era la complejidad operativa. Kafka no solo requería gestionar el propio clúster de brokers, sino también componentes adicionales como ZooKeeper en sus versiones tradicionales, además de configuraciones avanzadas relacionadas con replicación, almacenamiento, particiones, tuning de JVM y optimización de rendimiento. Para muchas empresas, especialmente equipos pequeños o startups, operar correctamente un entorno Kafka podía convertirse en una tarea compleja y costosa.
A esto se sumaba el consumo de recursos. Kafka está desarrollado sobre Java y depende de la máquina virtual JVM, lo que implica una gestión de memoria y CPU más exigente. En entornos cloud, donde cada recurso utilizado tiene un coste económico directo, mantener grandes clústeres Kafka puede incrementar considerablemente el gasto en infraestructura.
Otro problema habitual aparecía en escenarios donde se necesitaba baja latencia y simplicidad. Muchas organizaciones querían aprovechar las ventajas del streaming de mensajes sin tener que dedicar equipos enteros a operar y mantener la plataforma. En la práctica, algunas empresas terminaban desplegando infraestructuras complejas para resolver necesidades relativamente simples de comunicación en tiempo real.
Es precisamente en este contexto donde surge Redpanda. Su objetivo principal es mantener las capacidades de escalabilidad y streaming de Kafka, pero eliminando gran parte de la complejidad técnica y operativa asociada históricamente a este tipo de sistemas.
Redpanda intenta resolver varios problemas al mismo tiempo:
- reducir la complejidad de despliegue y mantenimiento,
- disminuir el consumo de infraestructura,
- simplificar la configuración,
- mejorar la eficiencia del hardware,
- y ofrecer una experiencia más moderna para entornos cloud.
La idea no es reemplazar el modelo de streaming de mensajes, sino hacerlo más accesible y eficiente. Redpanda busca que las empresas puedan construir sistemas en tiempo real sin asumir toda la carga operativa que tradicionalmente implicaba trabajar con plataformas de streaming a gran escala.
¿Cómo funciona?
El funcionamiento de Redpanda se basa en una idea sencilla pero muy potente: tratar todos los datos como un flujo continuo de mensajes que se producen, almacenan y consumen en tiempo real.
En esencia, Redpanda actúa como un sistema intermedio entre aplicaciones que generan información (productores) y aplicaciones que la consumen (consumidores). Cuando una aplicación genera un mensaje, por ejemplo, “usuario ha comprado un producto” o “sensor ha enviado una lectura”, ese mensaje no se procesa directamente de forma aislada, sino que se envía a Redpanda para ser distribuido de manera ordenada y fiable a otros sistemas que lo necesiten.
A nivel conceptual, su funcionamiento se apoya en tres elementos principales:
Mensajes y streams
Todo comienza con los mensajes, que son pequeñas unidades de información. Estos mensajes se agrupan en flujos o streams, que representan categorías de datos. Por ejemplo:
- un stream de “compras”,
- un stream de “logs de sistema”,
- un stream de “datos de sensores”.
Redpanda organiza estos mensajes de forma secuencial, lo que permite mantener el orden y garantizar que los sistemas consumidores procesen la información de manera consistente.
Productores y consumidores
El modelo de trabajo se basa en un patrón desacoplado:
- Productores: aplicaciones que envían mensajes a Redpanda.
- Consumidores: aplicaciones que leen esos mensajes para procesarlos.
Lo importante aquí es que los productores no necesitan saber quién consume los datos, ni los consumidores necesitan saber quién los generó. Redpanda actúa como intermediario central que desacopla completamente ambos lados del sistema.
Esto permite que los sistemas sean más flexibles y escalables, ya que cada componente puede evolucionar de forma independiente.
Además de productores y consumidores, existe un concepto fundamental llamado consumer groups. Este mecanismo permite coordinar varios consumidores para que trabajen de forma conjunta sobre un mismo flujo de datos.
En este modelo, los consumidores que pertenecen al mismo grupo se reparten automáticamente el procesamiento de los mensajes de un topic. Es decir, cada mensaje es procesado únicamente por uno de los consumidores del grupo, lo que permite distribuir la carga y mejorar la escalabilidad del sistema.
Por ejemplo, si un topic tiene varias particiones, Redpanda asigna dichas particiones entre los consumidores del grupo de forma equilibrada, permitiendo el procesamiento en paralelo sin duplicar el trabajo. En cambio, si existen varios grupos de consumidores diferentes, cada grupo recibirá una copia completa de los mensajes, lo que permite que distintos sistemas consuman la misma información de forma independiente.
Este mecanismo es clave para construir sistemas escalables y tolerantes a fallos, ya que permite añadir o eliminar consumidores dinámicamente sin afectar al flujo de datos ni a los productores.
Topics y particiones
Para organizar el flujo de datos, Redpanda utiliza topics, que son como “canales” donde se publican los mensajes.
Cada topic puede dividirse en particiones, lo que permite distribuir la carga entre varios nodos del sistema. Esta partición es clave para la escalabilidad, ya que:
- permite procesar mensajes en paralelo,
- mejora el rendimiento,
- y garantiza alta disponibilidad.
Arquitectura interna simplificada
A nivel técnico, Redpanda está diseñado para ser más eficiente que Apache Kafka. En lugar de depender de múltiples servicios externos, Redpanda funciona como un sistema más integrado y ligero.
Su arquitectura está optimizada para:
- aprovechar múltiples núcleos de CPU de forma eficiente,
- reducir la latencia en la escritura y lectura de mensajes,
- minimizar el uso de memoria,
- y evitar cuellos de botella típicos de sistemas más complejos.
Esto lo consigue gracias a un diseño basado en ejecución por núcleo (thread-per-core), donde cada núcleo del procesador maneja su propio flujo de trabajo de manera independiente, reduciendo la contención entre procesos.
Semánticas de entrega y transacciones
En sistemas de mensajería como Apache Kafka o Redpanda, es fundamental entender cómo se garantiza el procesamiento de los mensajes. Esto se describe mediante las semánticas de entrega, que determinan cuántas veces puede ser entregado y procesado un mensaje en el sistema.
Existen tres modelos principales. El primero es at-most-once, donde un mensaje puede no llegar a procesarse si ocurre un fallo, ya que no se realizan reintentos. El segundo es at-least-once, en el que se garantiza que el mensaje será entregado, pero puede procesarse más de una vez en caso de reintentos o errores. Este es el modelo más habitual en sistemas reales. Por último, exactly-once, que asegura que cada mensaje se procesa una única vez, evitando tanto pérdidas como duplicados, aunque es el modelo más complejo de implementar.
Para lograr esta última semántica, se utilizan mecanismos adicionales como las transacciones. Las transacciones permiten agrupar varias operaciones de escritura en el sistema de forma atómica, es decir, garantizando que todas se ejecutan correctamente o ninguna se aplica. Esto es especialmente útil cuando un productor necesita enviar varios mensajes relacionados o cuando se requiere consistencia entre distintas operaciones.
En este contexto, las transacciones no constituyen una semántica de entrega en sí mismas, sino un mecanismo técnico que permite implementar la semántica exactly-once. Para utilizarlas, el productor debe configurarse con un identificador transaccional (transactional.id), lo que permite al sistema coordinar y asegurar la consistencia de las operaciones entre sesiones.
Flujo completo de funcionamiento
Si lo simplificamos, el flujo típico sería:
- Una aplicación genera un mensaje.
- Ese mensaje se envía a Redpanda en un topic.
- Redpanda lo almacena de forma ordenada y persistente.
- Uno o varios consumidores leen ese mensaje.
- Cada consumidor lo procesa según su lógica (analítica, notificaciones, almacenamiento, etc.).
Ejemplo completo de funcionamiento
Primero la instalación de Redpanda en local (en local es gratis durante 30 días, la versión self-managed).
Guía de instalación (Powershell):
>mkdir redpanda-quickstart
>cd redpanda-quickstart
>Invoke-WebRequest -Uri "https://docs.redpanda.com/redpanda-quickstart.tar.gz" -OutFile "redpanda.tar.gz"
>tar xzf redpanda.tar.gz
>cd docker-compose
>docker compose up -d
Explorando la consola de Redpanda
La consola de Redpanda (Redpanda Console) es una interfaz web intuitiva para desarrolladores que permite gestionar y depurar su clúster de Redpanda y sus aplicaciones. Esta sección ofrece ejemplos prácticos y escenarios para ayudarte a comprender cómo aprovechar Redpanda Console en diferentes casos de uso, como la observabilidad de datos, la gestión de Redpanda, el control de acceso y la conectividad.
Para acceder a la consola una vez levantados los contenedores de Redpanda hay que acceder a localhost:8080/admin y las credenciales por defecto son: “superuser” y “secretpassword”
Lo primero que se ve en la pagina principal es el estado del clúster, la salud y los brokers.
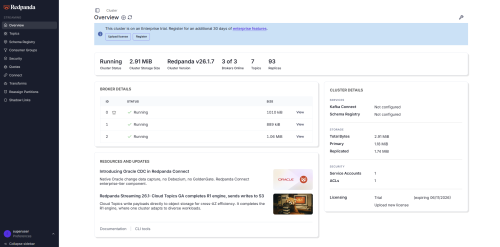
Para ver detalles de un broker concreto se selecciona la opción “view”.
Para ver los topics que hay se selecciona la sección topics:
Si se quiere crear un topic hay una opción “create topic”
Si se quiere ver información de un topic ya existente, (por ejemplo uno de estos tres que vienen por defecto), se hace clic en el topic y se abre la ventana.
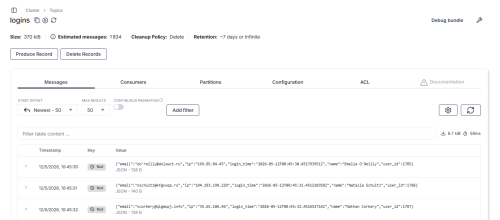
En este panel hay opciones como enviar o borrar mensaje de un topic, añadir filtros de búsqueda o ver información relativa al topic como los consumidores o particiones o diferentes configuraciones, ademas de los mensajes.
Otra funcionalidad que tiene la consola es la de crear “schemas”, que son definiciones de estructura que debe seguir todos los mensajes de un topic, por ejemplo:
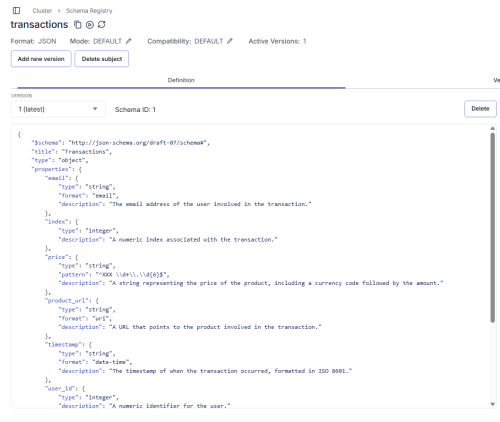
La sección Security en Redpanda es el área del sistema encargada de controlar el acceso a todos los recursos del clúster, definiendo quién puede interactuar con los datos y bajo qué condiciones.
En un sistema de streaming como Redpanda no todos los usuarios o servicios deben tener los mismos permisos, ya que se manejan flujos de información que pueden ser sensibles o críticos. Por eso, la seguridad se basa en establecer reglas claras que regulan el acceso.
Dentro de esta sección se pueden gestionar distintos elementos. Por un lado, los usuarios, que representan tanto personas como aplicaciones que se conectan al sistema. Por otro lado, los roles, que agrupan permisos concretos para facilitar la administración. También se incluyen las listas de control de acceso, conocidas como ACLs, que permiten definir de forma muy precisa qué puede hacer cada usuario sobre cada recurso del sistema.
Estas reglas pueden aplicarse a diferentes niveles. Por ejemplo, se puede permitir que un usuario tenga permisos de lectura sobre un topic concreto, como “logins”, pero impedir que pueda escribir o eliminar datos. De la misma forma, otro usuario podría tener permisos de escritura en un topic de “orders”, pero no acceso a topics relacionados con pagos o información sensible.
Un ejemplo práctico sería el de una arquitectura con varios servicios. Un microservicio de autenticación podría tener permiso para escribir mensajes de login, mientras que un sistema de analítica solo tendría acceso de lectura a esos datos. Por su parte, un servicio de pagos podría acceder únicamente a los topics relacionados con transacciones, evitando así cualquier exposición innecesaria de información.
En este contexto, la seguridad no solo sirve para proteger los datos, sino también para mantener el orden y la separación de responsabilidades entre los distintos componentes del sistema. Esto es especialmente importante en entornos distribuidos, donde múltiples equipos y servicios interactúan simultáneamente con la plataforma.
La seguridad viene por defecto activada en modo demo en entornos de desarrollo o quick start como el que tenemos, pero se puede configurar según el despliegue (docker, kubernetes, etc) y poner que esté activada por ejemplo solo para entornos de producción.
Otras funcionalidades que se puede acceder desde la interfaz web de Redpanda van más allá del trabajo básico con topics, productores y consumidores, y están orientadas principalmente a la administración avanzada del clúster y a escenarios de producción más complejos.
Entre ellas se encuentra Redpanda Connect, una herramienta que permite construir pipelines de datos para integrar el sistema con fuentes externas como bases de datos, almacenamiento en la nube o APIs, facilitando el movimiento y transformación de información sin necesidad de desarrollar código adicional.
También es posible gestionar la reasignación de particiones, una funcionalidad pensada para equilibrar la carga dentro del clúster. Esto permite mover particiones entre distintos brokers para optimizar el rendimiento o reaccionar ante fallos o saturación de nodos, asegurando así un funcionamiento más estable del sistema.
Otra sección disponible es la de quotas, que permite establecer límites de uso sobre usuarios o servicios. Con esta funcionalidad se puede controlar, por ejemplo, cuántos mensajes por segundo puede enviar un productor o cuántos recursos puede consumir un consumidor, evitando que un único servicio afecte al rendimiento global del clúster.
En niveles más avanzados también encontramos las transforms, que permiten procesar y transformar mensajes en tiempo real directamente dentro del flujo de datos. Esto hace posible modificar, filtrar o enriquecer mensajes sin necesidad de enviarlos a sistemas externos de procesamiento.
Por último, existen los shadow links, una funcionalidad más orientada a arquitecturas distribuidas complejas, que permite replicar o sincronizar datos entre distintos clústeres, algo especialmente útil en escenarios multi-región o de alta disponibilidad.
En conjunto, estas opciones representan capacidades avanzadas de Redpanda que complementan el uso básico del sistema y lo acercan a escenarios de producción reales, donde no solo se consume y produce información, sino que también se integra, controla y optimiza todo el flujo de datos de forma global.
Redpanda CLI (rpk)
Es la herramienta por terminal que permite hacer mediante linea de comandos las operaciones, (muchas de ellas se pueden hacer desde la consola pero Redpanda también ofrece esta opción).
Se debe escribir el usuario y contraseña del superusuario anteriormente mencionado en cada comando (o crear otro usuario si se quiere probar la parte de seguridad, pero para esta prueba se usará el superusuario). Esto se puede evitar creando perfiles para almacenar la información del usuario y contraseña para esa sesión de rpk.
Ejemplos de algunos comandos básicos: (en el caso de esta demo son desde dentro del contenedor)
Ver estado del clúster:
> rpk cluster info -X user=superuser -X pass=secretpassword
Listar topics:
> rpk topic list -X user=superuser -X pass=secretpassword
Crear un topic:
> rpk topic create demo-topic -X user=superuser -X pass=secretpassword
Productor (enviar mensajes):
> rpk topic produce demo-topic -X user=superuser -X pass=secretpassword
(y luego escribir, cada linea es 1 mensaje)
Consumidor (leer mensajes):
> rpk topic consume demo-topic -X user=superuser -X pass=secretpassword
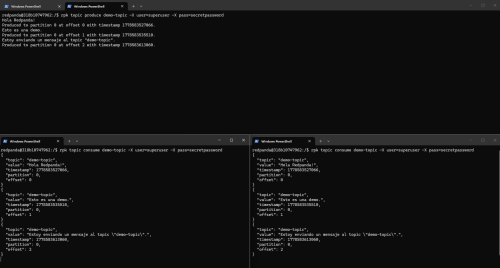
En la siguiente imagen hay un ejemplo muy sencillo de un productor y dos consumidores en tiempo real.
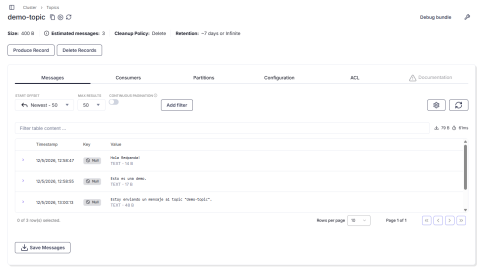
Además como se puede ver en la siguiente imagen, también se puede ver el topic creado y los mensajes en la interfaz web. Ademas podemos usar las diferentes herramientas como crear, borrar mensaje, o filtrar.
Ejemplo de integración con Java
Para el ejemplo de Java se presentan 2 clases, un productor y un consumidor. Los conectores son exactamente los mismos que si se usa Kafka, la misma librería “kafka-clients” en el pom y las mismas clases. Por eso se dice que Redpanda es compatible con Kafka, simplemente se tiene que cambiar la dirección donde están los brokers y el código sería el mismo.
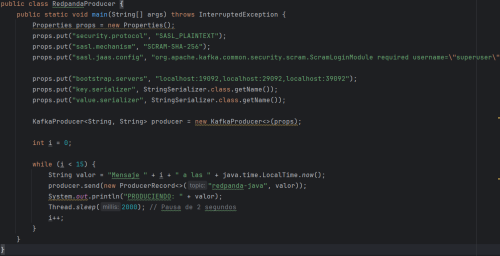
Para el productor se usan clases como KafkaProducer o ProducerRecord. En la siguiente imagen se ve la clase RedpandaProducer.
Para el consumidor se usan clases como KafkaConsumer o ConsumerRecord. En la siguiente imagen se puede ver la clase RedpandaConsumer.
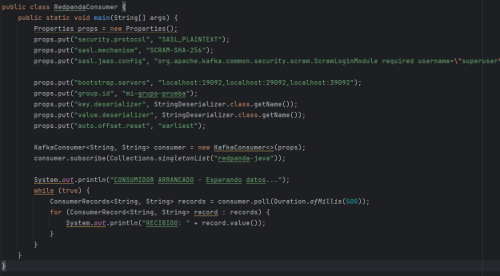
Para ambas clases hay que establecer propiedades como las direcciones de los servidores, configuraciones de seguridad, usuario y contraseña, etc.
Para ejecutar este ejemplo sencillo, simplemente se tiene que arrancar Redpanda como se ha indicado en el punto anterior y después arrancar el consumidor y luego el productor.
Ventajas frente a Apache Kafka
Las ventajas de Redpanda frente a Apache Kafka se entienden sobre todo cuando se compara cómo están construidos y cómo se operan en la práctica, más que por diferencias funcionales visibles para el usuario.
Una de las principales ventajas es el rendimiento y la latencia. Al estar desarrollado en C++ y usar una arquitectura nativa sin máquina virtual ni garbage collector, Redpanda tiende a ofrecer una latencia más estable y predecible, especialmente bajo carga alta, evitando pausas internas típicas de sistemas basados en la JVM como Kafka.
Otra ventaja importante es la simplicidad operativa. Redpanda está diseñado como un sistema “todo en uno”, donde el propio broker incluye muchas capacidades integradas sin necesidad de desplegar componentes adicionales complejos. En Kafka, en cambio, es habitual depender de más piezas del ecosistema (como Zookeeper en versiones antiguas o servicios externos en arquitecturas modernas), lo que puede aumentar la complejidad de despliegue y mantenimiento.
También destaca el consumo de recursos. Gracias a su modelo de ejecución por núcleos (sin bloqueo entre hilos), Redpanda suele aprovechar mejor el hardware moderno y requiere menos ajustes finos para escalar, mientras que Kafka puede necesitar más configuración para obtener un rendimiento óptimo en escenarios exigentes.
Por último, Redpanda ofrece una experiencia más unificada para desarrolladores y operaciones, ya que incluye herramientas integradas como consola, CLI y funcionalidades de administración que simplifican el trabajo diario con el sistema.
Casos de uso
Los casos de uso de Redpanda se centran en escenarios donde es necesario procesar grandes volúmenes de datos en tiempo real, especialmente cuando la baja latencia y la simplicidad operativa son importantes. Al ser compatible con el ecosistema de Apache Kafka, puede utilizarse en muchos de los mismos contextos, pero con ventajas en rendimiento y facilidad de despliegue.
Uno de los casos de uso más habituales es el procesamiento de mensajes en tiempo real, como logs de aplicaciones, métricas de sistemas o actividad de usuarios. Por ejemplo, cada vez que un usuario inicia sesión, realiza una acción o genera un mensaje en una plataforma, ese dato puede enviarse a Redpanda para ser procesado al instante por sistemas de analítica, monitorización o detección de anomalías.
Otro caso muy común es la arquitectura de microservicios. En este tipo de sistemas, Redpanda actúa como un bus de mensajes central donde los distintos servicios publican y consumen información de forma desacoplada. Por ejemplo, un servicio de pedidos puede emitir mensajes cuando se crea una compra, y otros servicios como facturación, inventario o envío reaccionan a esos mensajes de forma independiente.
También se utiliza en sistemas de analítica en tiempo real, donde es necesario procesar datos continuamente para generar dashboards o indicadores actualizados al segundo. Esto es especialmente útil en sectores como e-commerce, fintech o plataformas digitales, donde la información cambia constantemente y tiene valor inmediato.
Otro caso relevante es el de la ingesta de datos desde múltiples fuentes, como bases de datos, APIs o sistemas externos. Con herramientas como Redpanda Connect, estos datos pueden centralizarse en un flujo continuo que alimenta sistemas de almacenamiento, machine learning o procesamiento posterior.
En general, Redpanda se utiliza en cualquier arquitectura donde los datos no se procesan en lotes, sino como un flujo continuo de mensajes que deben ser capturados, transportados y procesados en tiempo real.
¿Cuándo elegir Redpanda y cuándo Kafka?
Elegir entre Redpanda y Apache Kafka depende más del contexto del proyecto que de diferencias funcionales directas, ya que ambos cumplen el mismo objetivo: procesar mensajes en tiempo real.
En general, Redpanda se suele elegir cuando se busca simplicidad operativa y despliegue rápido. Es una buena opción en equipos pequeños o medianos, entornos cloud modernos o proyectos donde no se quiere gestionar demasiada infraestructura. También encaja bien cuando la prioridad es tener baja latencia y un rendimiento estable sin necesitar mucha configuración, especialmente en sistemas de analítica en tiempo real, observabilidad o pipelines de datos.
Kafka, por otro lado, suele ser la opción elegida en entornos donde ya existe un ecosistema consolidado alrededor de él o cuando se necesita máxima madurez, compatibilidad histórica y un ecosistema muy amplio de herramientas y conectores. Es habitual en grandes organizaciones que llevan años construyendo arquitectura sobre Kafka y tienen equipos especializados en su operación.
En resumen, Redpanda se elige más por eficiencia y facilidad de uso en arquitecturas modernas, mientras que Kafka sigue siendo una apuesta muy sólida cuando se prioriza estabilidad a largo plazo.
Comparativa de rendimientos
Para la comparativa de rendimientos entre Redpanda y Kafka, están los datos obtenidos de la siguiente documentación oficial:
https://www.redpanda.com/blog/redpanda-vs-kafka-performance-benchmark
En este documento se puede ver como el rendimiento en Redpanda es superior a Kafka y ademas también se puede ver como el coste de hardware es menor.
En primer lugar explica las características y las condiciones de cada benchmark, Y después de eso pasa a comparar los rendimientos con diferentes velocidades de escritura.
Las conclusiones que tiene el documento anterior son las que se ven en la siguiente tabla.
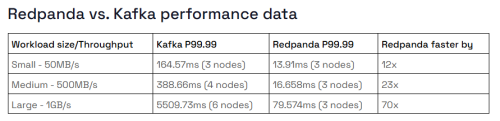
Como se puede apreciar, a mayor carga de trabajo, Redpanda incrementa su ventaja en el rendimiento frente a Kafka.
Conclusión
En conclusión, Redpanda aparece como una evolución moderna del modelo de streaming de mensajes que popularizó Apache Kafka, manteniendo compatibilidad con su ecosistema pero simplificando bastante la forma en la que se despliega y se opera.
Su principal valor está en reducir la complejidad de la infraestructura, mejorar la experiencia de uso y ofrecer un rendimiento más predecible gracias a su arquitectura nativa en C++ y su diseño orientado a ejecución por núcleos. Esto lo hace especialmente atractivo para equipos que quieren trabajar con datos en tiempo real sin asumir la carga operativa típica de sistemas más tradicionales.
Kafka, por su parte, sigue siendo una opción muy sólida y ampliamente adoptada, con un ecosistema muy maduro y probado en grandes organizaciones, lo que lo mantiene como estándar en muchos entornos empresariales.
En conjunto, no se trata tanto de que uno “reemplace” al otro en todos los casos, sino de que Redpanda ofrece una alternativa más moderna y simplificada para muchos escenarios, mientras Kafka sigue siendo una apuesta segura en arquitecturas ya establecidas o altamente complejas.
Documentación oficial de Redpanda: https://docs.redpanda.com/current/home/

Francisco Fernández
Técnico de Software
ALTIA



